Корреляционно-регрессионный анализ
Министерство образования Российской Федерации
ОРЕНБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Финансово-экономический факультет
Кафедра МММЭ
КОНТРОЛЬНАЯ РАБОТА
по дисциплине "Эконометрика"
Корреляционно-регрессионный анализ
ОГУ 061700.5001.03 00
Руководитель работы
__________________ Аралбаева Г.Г.
“____”_____________2002г.
Исполнитель
студент гр.99 з/о ст
______________.Чаплыгина О.Г.
“_____”____________2002г.
Оренбург 2002 г.
Задание
Дана выборка из генеральной совокупности по производственно-хозяйственной деятельности предприятия машиностроения (Приложение 1). Исследуется N=53 объекта по пяти признакам:
X5 –Удельный вес рабочих в составе ППП;
X7 –Коэффициент сменности оборудования;
X10 -Фондоотдача;
X14–Фондовооруженность труда;
X17 – Непроизводственные расходы;
Y1- производительность труда;
На основе полученных данных необходимо:
На основе данных необходимо:
1. По исходным данным построить классическую линейную модель множественной регрессии, оценить значимость полученного уравнения регрессии и его коэффициентов, для значимых параметров построить доверительный интервал.
2. Проанализировать матрицу парных коэффициентов корреляции на наличие мультиколинеарности, если мультиколлинеарность присутствует устранить методом пошагового отбора переменных, отобрать наиболее информативные переменные и с помощью них построить модель регрессии, оценить ее значимость.
3. Проверить построенную модель на гетероскедастичность. Построить обобщенную модель множественной регрессии (случай гетероскедастичности остатков)
4. Проверить модель на наличие автокорреляции (с помощью критерия Дарбина-Уотсона) устранить с использованием обобщенного метода наименьших квадратов на случай автокоррелированности регрессионных остатков
Введение
Пусть имеется p объясняющих переменных ![]() и зависимая переменная У. Переменная У является случайной величиной, имеющей при заданных значениях факторов некоторое распределение. Если случайная величина Y непрерывна, то можно считать, что ее распределение при каждом допустимом наборе значений факторов (
и зависимая переменная У. Переменная У является случайной величиной, имеющей при заданных значениях факторов некоторое распределение. Если случайная величина Y непрерывна, то можно считать, что ее распределение при каждом допустимом наборе значений факторов (![]() ) имеет условную плотность
) имеет условную плотность ![]() .
.
Обычно делается некоторое предположение относительно распределения У. Чаще всего предполагается, что условные распределения У при каждом допустимом значении факторов – нормальные. Подобное предположение позволяет получить значительно более «продвинутые» результаты.
Объясняющие переменные ![]() могут считаться как случайными, так и детерминированными, т.е. принимающими определенные значения.
могут считаться как случайными, так и детерминированными, т.е. принимающими определенные значения.
Классическая эконометрическая модель рассматривает объясняющие переменные ![]() как детерминированные, однако, основные результаты статистического исследования модели остаются в значительной степени теми же, что и в случае, если считать
как детерминированные, однако, основные результаты статистического исследования модели остаются в значительной степени теми же, что и в случае, если считать ![]() случайными переменными.
случайными переменными.
Объясняющая часть – обозначим ее Уе – в любом случае представляет собой функцию от значений факторов – объясняющих переменных:
![]()
Таким образом, эконометрическая модель имеет вид
![]()
Наиболее естественным выбором объясненной части случайной величины У является ее среднее значение – условное математическое ожидание ![]() , полученное при данном наборе значений объясняющих переменных (х1,x2,..,xp)
, полученное при данном наборе значений объясняющих переменных (х1,x2,..,xp)
Цель работы: Исследовать корреляционно – регрессионную зависимость между признаком у и группой аргументов ![]() .
.
Объект исследования : Производственные предприятия, занимающиеся производственной деятельностью.
Предмет исследования : корреляционная связь между признаками.
1. По исходным данным построить классическую линейную модель множественной регрессии, оценить значимость полученного уравнения регрессии и его коэффициентов, для значимых параметров построить доверительный интервал.
Построим собственно-линейную функцию регрессии вида: ![]() , оценка
, оценка ![]()
Параметры модели будем искать МНК: ![]()
Матрица Х имеет размерность 6х53, в первой строке стоят единицы.
Используя пакет STADIA оцениваем уравнение регрессии.
Получаем следующие результаты:
Таблица 1
Коэфф. a0 a1 a2 a3 a4 a5
Значение -14,9 14,4 4 0,906 0,174 0,237
Ст.ошиб. 18,4 19,8 2,91 0,992 0,188 0,216
Значим. 0,575 0,523 0,172 0,631 0,637 0,278
Источник Сум.квадр. Степ.св Средн.квадр.
Регресс. 37,2 5 7,44
Остаточн 292 47 6,22
Вся 330 52
Множеств R R^2 R^2прив Ст.ошиб. F Значим
0,33602 0,11291 0,01854 2,4942 1,2 0,325
Гипотеза 0: <Регрессионная модель неадекватна экспериментальным данным>
Оценка уравнения регрессии:
![]() =-14,9+14,4х1+4,0х2+0,906х3 +0,174х4+0,237х5
=-14,9+14,4х1+4,0х2+0,906х3 +0,174х4+0,237х5
(18,4) (19,8) (2,91) (0,992) (0.188) (0.216)
(внизу указаны стандартные ошибки каждого коэффициента регресии.)
Проверка значимости модели.
Проверим значимость построенной модели, выдвигаем гипотезу
H0: ![]() (модель незначима)
(модель незначима)
H1: ![]() (модель значима)
(модель значима)
Строим статистику ![]() распределена по закону Фишера-Снедокора с числом ст. свободы n в числители и N-n-1 в знаменатели. (воспользуемся данными таблицы 1)
распределена по закону Фишера-Снедокора с числом ст. свободы n в числители и N-n-1 в знаменатели. (воспользуемся данными таблицы 1)
В нашем случае F=1,2, Fкр (0,05;5;47)=2,44 т.к Fн>Fкр,то гипотеза Н0 не отвергается и модель не является значимой.
Проверка значимости коэффициентов регрессии.
Проверим на значимость коэффициенты уравнения, выдвигаем гипотезу
Н0:![]()
Н1: ![]()
Строим статистику t=![]() распределена по закону Стьюдента с N-n-1 ст.свободы. (воспользуемся данными таблицы 1) (будем принимать коэффициенты регрессии по абсолютному значению)
распределена по закону Стьюдента с N-n-1 ст.свободы. (воспользуемся данными таблицы 1) (будем принимать коэффициенты регрессии по абсолютному значению)
tb0 =- 0,810 tb3 =0,913
tb1 =0,727 tb=0,926
tb2 =1,375 tb5 =1,097
tкр(0,05;47)=2,013
tb0 ->-tкр tb3 tb1 < tкр tb4 < tкр tb2 < tкр tb5 < tкр Среди всех коэффициентов значимыми являются b0, по такой модели прогноз сделать не представляется возможным, поскольку все коэффициенты регрессии при переменных не значимы. На этом регрессионный анализ можно завершить, так как значимых переменных не обнаружено. 2. Проанализировать матрицу парных коэффициентов корреляции на наличие мультиколинеарности, если мультиколлинеарность присутствует устранить методом пошагового отбора переменных, отобрать наиболее информативные переменные и с помощью них построить модель регрессии, оценить ее значимость. Коэффициент ковариации нормированных случайных величин называется коэффициентом корреляции, или коэффициентом парной корреляции. где Для удобства расчета корреляционной матрицы, предварительно рассчитывают ковариационную матрицу . Ковариационная матрица определяется как математическое ожидание произведения центрированного случайного вектора на этот транспонированный вектор Матрица где Рассмотрим матрицу исходных данных (см. Приложение 1) 1. Найдем центрированную матрицу Найдем оценку вектора где Используя пакет STADIA (Раздел описательная статистика), получаем вектор Согласно приведенной формуле 2. Рассчитываем матрицу Используя пакет STADIA (меню преобразований), получаем: Оценку ковариационной матрицы получим путем умножения матрицы Обозначим оценку ковариационной матрицы S, используя пакет MathCad находим: оценка ковариационной матрицы. Для расчета ковариационной матрицы воспользуемся формулой (1) и определением ковариационной матрицы (2), получаем следующую оценку корреляционной матрицы: Данный расчет можно провести на прямую, используя пакет STADIA, но наша цель бала показать весь процесс расчета корреляционной матрицы. Проанализируем корреляционную матрицу. 1 – я строка и 1 – столбец это признак у , как видим наибольшая связь наблюдается между признаками х7 и х14 очень тесная (-0,938) , если анализировать парную связь между факторными признаками, то можно заметить наибольшую связь между признаком х5 и х17 (-0,938). Устранение мультиколлинеарности с помощью метода пошаговой регрессии Устраним мультиколлинеарность методом пошаговой регрессии, который предполагает, что на каждом шаге мы будем включать в уравнение регрессии тот признак, который будет вызывать наибольшее приращение коэффициента детерминации. Шаг 1 Строим уравнения регрессии Находим максимальный коэффициент детерминации Вычисляем нижнюю границу коэффициента детерминации Используя пакет STADIA определяем: Шаг 2 Строим уравнения регрессии Находим максимальный коэффициент детерминации Вычисляем нижнюю границу коэффициента детерминации Используя пакет STADIA определяем: Шаг 3 Строим уравнения регрессии Находим максимальный коэффициент детерминации Вычисляем нижнюю границу коэффициента детерминации Используя пакет STADIA определяем: Процесс прекращаем поскольку, Подробный анализ, выполненный с помощью программы “Stadia”, приведен в Приложении 1. Граф.1 Подробные расчеты см. Приложение 1 Таким образом , из анализа исключаются все факторные признаки, кроме Х7,X9 2. Проверить построенную модель на гетероскедастичность. Построить обобщенную модель множественной регрессии (случай гетероскедастичности остатков) 1.4 Построение и исследование новой модели регрессии. 1.4.1 Вычисление оценок коэффициентов регрессии Регрессионная модель примет вид: Вывод т.к. Проверка значимости и построение доверительных интервалов для коэффициентов регрессии Проверим значимость уравнения регрессии: H0:<регрессионная модель незначима> H1:<регрессионная модель значима> Fвычисленное=57.1 Fкритическое (0,05;2;24)=3,40 так как Fвычисленное >Fкритическое , то принимается гипотеза Н1 , следовательно в уравнении коэффициенты регрессии должны быть значимыми. Проверим значимость коэффициентов регрессии tвычисленное = . . коэффициенты значимы, поскольку Построим доверительный интервал для коэффициентов по формуле: где Используя пакет STADIA находим доверительный интервал для коэффициента при переменной Х7,Х9. 1.4.2 Построение доверительного интервала для результативного признака где t-значение статистики Стьюдента при степенях свободы. Построим доверительный интервал прогноза в точке Критерий ранговой корреляции Спирмена. По выборочным данным строим регрессионную модель, которую оцениваем с помощью МНК. Вычисляем регрессионные остатки: еi=уi-ýi. Данные объясняющих переменных и остатки ранжируют, после чего исследуют зависимость между хi и εi. Для этого выдвигаем гипотезу Нo: нет зависимости между объясняющей переменной и регрессионными остатками ( она равносильна гипотезе о том, что нет явления гетероскедастичности), Нı: есть зависимость, т.е. явление гетероскедастичности наблюдается. Для проверки гипотезы строится статистика, распределенная нормально с математическим ожиданием равным нулю и дисперсией равной 1: t= где Rx,e=1-6* На заданном уровне значимости α=0.05 по таблице нормального распределения находим tкр Если tн>t, то нулевую гипотезу отвергаем, значит есть явления гетероскеластичности, в противном случае явление гетероскедастичности наблюдаем. В случае наличия гетероскедастичности, используя ОМНК оценим регрессию, взяв в качестве матрицы Ω= rang xi rang ei Di Di2 21.3 69.2 77.9 17.1 18.4 37.9 72.2 27.5 58.2 46.2 74 43.5 18.8 59.5 52.2 65.1 60.2 2.63 84 19.8 78.7 62 104 69.3 78.9 15.1 51.5 84.98 30.58 38.42 60.34 60.22 60.79 29.82 70.57 34.51 64.73 36.63 32.84 62.64 34.07 39.27 28.46 30.27 69.04 25.42 53.13 28.00 38.79 32.04 38.58 18.51 57.62 20.80 -0.917 2.18 0.808 -5 -7.52 -17.5 7.55 -10.2 11.5 -21.7 2.23 0.909 -7.49 19.7 4.75 -10.3 11.9 10.8 -4.14 -8.63 -6.32 -13.4 -3.89 -5.4 -1.42 19.6 32 2,5 19,5 24 4,5 2,5 8,5 18 8,5 14 11 21 10 7 12,5 12,5 16 19,5 4,5 26 6 22 16 27 23 25 1 16 15 18 16 11 7 2 21 5 23 1 19 17 8 26 20 4 24 22 12 6 9 3 13 10 14 25 27 -15 -18 8 -11 -7 -2 -3 -5 -9 10 2 -7 -1 -26 -20 12 -24 -22 14 0 13 13 14 13 11 -24 -11 225 324 64 121 49 4 9 25 81 100 4 49 1 676 400 144 576 484 196 0 169 169 196 169 121 576 121 rang xi rang ei Di Di2 21.3 69.2 77.9 17.1 18.4 37.9 72.2 27.5 58.2 46.2 74 43.5 18.8 59.5 52.2 65.1 60.2 2.63 84 19.8 78.7 62 104 69.3 78.9 15.1 51.5 84.98 30.58 38.42 60.34 60.22 60.79 29.82 70.57 34.51 64.73 36.63 32.84 62.64 34.07 39.27 28.46 30.27 69.04 25.42 53.13 28.00 38.79 32.04 38.58 18.51 57.62 20.80 -0.917 2.18 0.808 -5 -7.52 -17.5 7.55 -10.2 11.5 -21.7 2.23 0.909 -7.49 19.7 4.75 -10.3 11.9 10.8 -4.14 -8.63 -6.32 -13.4 -3.89 -5.4 -1.42 19.6 32 21 10 5 25 22,5 20 2,5 26 11 15 4 16 24 6,5 13 2,5 18 27 6,5 22,5 1 8 14 12 9 17 19 15 18 16 11 7 2 21 5 23 1 19 17 8 26 20 4 24 22 12 6 9 3 13 10 14 25 27 6 -8 -11 14 -7 18 -21 21 -12 14 -15 -1 16 -26 -7 -4 -6 5 -12 -6 -8 5 1 2 -5 -8 -8 36 64 121 196 49 324 441 441 144 196 225 1 256 676 49 16 36 25 144 36 64 25 1 4 25 64 64 Если явление гетероскедастичности наблюдается, то оценки, полученные с помощью МНК, являются смещенными и состоятельными. В этом случае следует использовать ОМНК для построения коэффициентов регрессии: bомнк=(ΧТΩˉ¹X)ˉ¹X ТΩˉ¹Y, где Ω - диагональная матрица, которую необходимо оценить. Тогда оценка регрессии будет иметь вид:Ŷ=Xbомнк. Проверка на значимость уравнения регрессии осуществляется с помощью статистики , распределенной по закону Фишера -Снедокера. FН= Проверка на значимость коэффициентов регрессии осуществляется с помощью статистики, распределенной по закону Стьюдента. tн= Поскольку гетероскедастичности нет ,то нет необходимости применения ОМНК. На практике можно провести примеры, когда построенная регрессионная модель оказывается значимой, дисперсии оценок этой модели малы, но модель оказывается неадекватной описываемому процессу. Причина этого может быть в наличии явления автокорреляции - это явление, заключающееся в том, что значения случайной составляющей в любом наблюдении зависит от его значений во всех других наблюдениях. Если в этом случае проанализировать поведение остатков, то зачастую можно выявить следующие тенденции: ● значения регрессионных остатков в соседних точках оказываются одного знака. В данном случае имеет место положительная автокорреляция. ● значения регрессионных остатков в соседних точках оказываются разного знака (по закономерности ). В этом случае имеет место отрицательная автокорреляция остатков. Явление автокорреляции по поведению остатков можно выявить, если достаточна частота наблюдений. Автокорреляция выявляется с помощью статистики Дарбина- Уотсона: d= Если наличие автокорреляции отсутствует, то значение статистики должно быть близкой к двум. При наличии положительной автокорреляции величина d близка к нулю (меньше двух); при отрицательной автокорреляции она близка к значению 4. Вычисляют верхнюю 1) Если d 2) Если d>d 3) Если d В случае наличия автокорреляции ее необходимо устранить, т.к построенные оценки коэффициентов регрессии будут смещенными и состоятельными. В литературе большое внимание уделяется зависимости первого порядка между регрессионными остатками: Таким образом, указали вид ковариационной матрицы вектора регрессионных остатков. Для оценки коэффициентов регрессии ОМНК необходимо построить матрицу. Используя вид На практике величина 1. Оценивается регрессия МНК: У=Х 2. Вычисляются остатки e 3. Оценивается регрессионная зависимость е 4. Строится 5. Повторно вычисляют е Процесс заканчивается, когда значения Таким образом указан один из способов построения матрицы Проверим наличие автокорреляции в модели. Составим расчетную таблицу: d= Поскольку d>2 то альтернатива отсутствию автокорреляции будет существование отрицательной автокорреляции. По таблице находим для n=27, k=2 (число объясняющих переменных) и уровня значимости a=0,05 : d1=1.24 и d2 = 1.56 Т.к. 4 – d= 1.809 > d2=1.56 следовательно автокорреляции нет. Наша цель- построить ковариационную матрицу вектора регрессионных остатков, найти ее оценку и построить модель ОМНК. Исследуем случайные величины Таким образом, указали вид ковариационной матрицы вектора регрессионных остатков. Для оценки коэффициентов регрессии ОМНК необходимо построить матрицу. Используя вид На практике величина 6. Оценивается регрессия МНК: У=Х 7. Вычисляются остатки e 8. Оценивается регрессионная зависимость е 9. Строится 10. Повторно вычисляют е Процесс заканчивается, когда значения Таким образом указан один из способов построения матрицы Поскольку автокорреляции нет, то нет необходимости применения ОМНК. Y1 X5 X7 X10 X14 X17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 9.26 9.38 12.11 10.81 9.35 9.87 8.17 9.12 5.88 6.30 6.22 5.49 6.50 6.61 4.32 7.37 7.02 8.25 8.15 8.72 6.64 8.10 5.52 9.37 13.17 6.67 6.68 6.22 10.02 8.16 6.78 6.48 10.44 7.65 8.77 7.00 11.06 9.02 13.28 9.27 6.70 6.69 9.42 7.24 5.39 5.61 5.59 6.57 6.54 4.23 5.22 18.00 11.03 0.78 0.75 0.68 0.70 0.62 0.76 0.73 0.71 0.69 0.73 0.68 0.74 0.66 0.72 0.68 0.77 0.78 0.78 0.81 0.79 0.77 0.78 0.72 0.79 0.77 0.80 0.71 0.79 0.76 0.78 0.62 0.75 0.71 0.74 0.65 0.66 0.84 0.74 0.75 0.75 0.79 0.72 0.70 0.66 0.69 0.71 0.73 0.65 0.82 0.80 0.83 0.70 0.74 1.37 1.49 1.44 1.42 1.35 1.39 1.16 1.27 1.16 1.25 1.13 1.10 1.15 1.23 1.39 1.38 1.35 1.42 1.37 1.41 1.35 1.48 1.24 1.40 1.45 1.40 1.28 1.33 1.22 1.28 1.47 1.27 1.51 1.46 1.27 1.43 1.50 1.35 1.41 1.47 1.35 1.40 1.20 1.15 1.09 1.26 1.36 1.15 1.87 1.17 1.61 1.34 1.22 1.45 1.30 1.37 1.65 1.91 1.68 1.94 1.89 1.94 2.06 1.96 1.02 1.85 0.88 0.62 1.09 1.60 1.53 1.40 2.22 1.32 1.48 0.68 2.30 1.37 1.51 1.43 1.82 2.62 1.75 1.54 2.25 1.07 1.44 1.40 1.31 1.12 1.16 0.88 1.07 1.24 1.49 2.03 1.84 1.22 1.72 1.75 1.46 1.60 1.47 1.38 1.41 1.39 6.40 7.80 9.76 7.90 5.35 9.90 4.50 4.88 3.46 3.60 3.56 5.65 4.28 8.85 8.52 7.19 4.82 5.46 6.20 4.25 5.38 5.88 9.27 4.36 10.31 4.69 4.16 3.13 4.02 5.23 2.74 3.10 10.44 5.65 6.67 5.91 11.99 8.30 1.63 8.94 5.82 4.80 5.01 4.12 5.10 3.49 4.19 5.01 11.44 7.67 4.66 4.30 6.62 47750 50391 43149 41089 14257 22661 52509 14903 25587 16821 19459 12973 50907 6920 5736 26705 20068 11487 32029 18946 28025 20968 11049 45893 99400 20719 36813 33956 17016 34873 11237 17306 39250 19074 18452 17500 7888 58947 94697 29626 11688 21955 12243 20193 20122 7612 27404 39648 43799 6235 11524 17309 22225 Приложение 2. Y1 цен X5 цен X7 цен X10 цен X14 цен X17 цен 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 424344454647484950515253 1,2 1,32 4,05 2,75 1,29 1,81 0,11 1,06 -2,18 -1,76 -1,84 -2,57 -1,56 -1,45 -3,74 -0,69 -1,04 0,19 0,09 0,66 -1,42 0,04 -2,54 1,31 5,11 -1,39 -1,38 -1,84 1,96 0,1 -1,28 -1,58 2,38 -0,41 0,71 -1,06 3 0,96 5,22 1,21 -1,36 -1,37 1,36 -0,82 -2,67 -2,45 -2,47 -1,49 -1,52 -3,83 -2,84 9,94 2,97 0,045 0,015 -0,055 -0,035 -0,115 0,025 -0,005 -0,025 -0,045 -0,005 -0,055 0,005 -0,075 -0,015 -0,055 0,035 0,045 0,045 0,075 0,055 0,035 0,045 -0,015 0,055 0,035 0,065 -0,025 0,055 0,025 0,045 -0,115 0,015 -0,025 0,005 -0,085 -0,075 0,105 0,005 0,015 0,015 0,055 -0,015 -0,035 -0,075 -0,045 -0,025 -0,005 -0,085 0,085 0,065 0,095 -0,035 0,005 0,03 0,15 0,1 0,08 0,01 0,05 -0,18 -0,07 -0,18 -0,09 -0,21 -0,24 -0,19 -0,11 0,05 0,04 0,01 0,08 0,03 0,07 0,01 0,14 -0,1 0,06 0,11 0,06 -0,06 -0,01 -0,12 -0,06 0,13 -0,07 0,17 0,12 -0,07 0,09 0,16 0,01 0,07 0,13 0,01 0,06 -0,14 -0,19 -0,25 -0,08 0,02 -0,19 0,53 -0,17 0,27 0 -0,12 -0,08 -0,23 -0,16 0,12 0,38 0,15 0,41 0,36 0,41 0,53 0,43 -0,51 0,32 -0,65 -0,91 -0,44 0,07 0 -0,13 0,69 -0,21 -0,05 -0,85 0,77 -0,16 -0,02 -0,1 0,29 1,09 0,22 0,01 0,72 -0,46 -0,09 -0,13 -0,22 -0,41 -0,37 -0,65 -0,46 -0,29 -0,04 0,5 0,31 -0,31 0,19 0,22 -0,07 0,07 -0,06 -0,15 -0,12 -0,14 0,43 1,83 3,79 1,93 -0,62 3,93 -1,47 -1,09<
Подобные работы: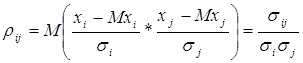 , (1)
, (1)![]() - средние квадратические отклонения случайных величин
- средние квадратические отклонения случайных величин ![]() и
и ![]()
![]()
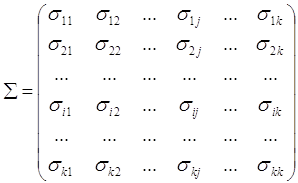 (2)
(2)![]() - центральный смешанный момент второго порядка, коэффициент ковариации i- й и j-й компонент вектора
- центральный смешанный момент второго порядка, коэффициент ковариации i- й и j-й компонент вектора ![]() при
при ![]()
![]() , где Х матрица исходных данных размерности 53*6
, где Х матрица исходных данных размерности 53*6![]() , т.е.
, т.е.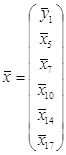
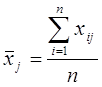 , где n = 53 – объем выборки.
, где n = 53 – объем выборки.![]() :
: 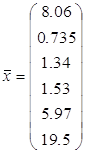
![]() рассчитываем центрированную матрицу (Приложение 2)
рассчитываем центрированную матрицу (Приложение 2)![]()
![]() =
=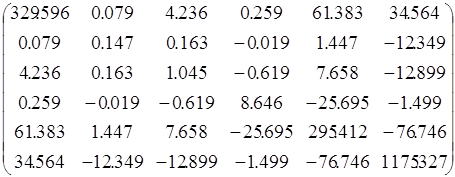
![]() на множитель
на множитель ![]()
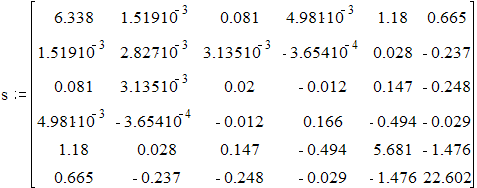
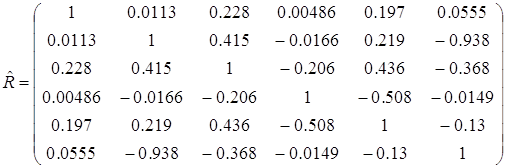
![]()
![]() (где k=1)
(где k=1)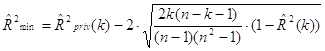 достигнет своего максимума.
достигнет своего максимума.Переменная ![]()
![]()
k X17 0.191 0.7117 1 ![]()
![]() (где k=1) достигнет своего максимума.
(где k=1) достигнет своего максимума.Переменная ![]()
![]()
k X7 0.7618 0.7117 1 Х7,Х9 0.8118 0.750 2 ![]()
![]() (где k=1) достигнет своего максимума.
(где k=1) достигнет своего максимума.Переменная ![]()
![]()
k X7 0.7618 0.7117 1 Х7,Х9 0.8118 0.750 2 Х7,Х9,X3 0.80953 0.735 3 ![]() меньше таких коэффициентов для уравнений регрессии с двумя переменными.
меньше таких коэффициентов для уравнений регрессии с двумя переменными.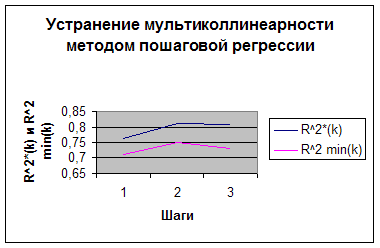
![]()
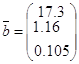
![]()
![]() около 1, то можно считать , что связь тесная.
около 1, то можно считать , что связь тесная.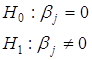 tкритическое =2.064
tкритическое =2.064![]() коэффициент значим.
коэффициент значим.![]() коэффициент значим
коэффициент значим![]() > tкритическое =2.064,
> tкритическое =2.064, ![]() <tкритическое ,
<tкритическое ,![]()
![]() остаточная дисперсия
остаточная дисперсия![]()
![]()
![]() Доверительный интервал для результативного признака будем строить , исходя из формулы:
Доверительный интервал для результативного признака будем строить , исходя из формулы:![]()
![]() ,
,![]() и
и ![]()
![]()
![]() , используя пакет STADIA ,находим:
, используя пакет STADIA ,находим:![]()
2. Исследование модели на наличие гетероскедастичности
![]() Rх.е ,
Rх.е , 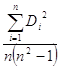 -коэффициент ранговой корреляции Спирмена, где Di2= rang xi- rang ei .
-коэффициент ранговой корреляции Спирмена, где Di2= rang xi- rang ei .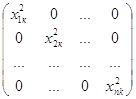
Проверим наличие гетероскедастичности по переменной Х7
![]()
![]()
![]()
![]()
Приведем график зависимости регрессионных остатков
![]() от изменения признака Х7.
от изменения признака Х7.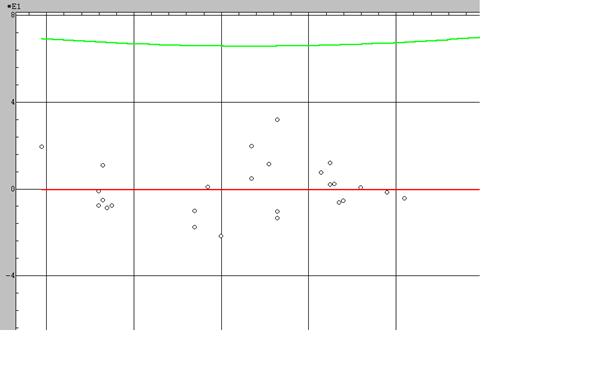
По оси ординат (У) отражено значение остатков , по оси абсцисс (х) значение признака. Как видно визуально гетероскедастичность отсутствует.
Ранговый коэффициент корреляции будет Rx,e= 0,0681, t=
![]() Rх.е =-0,3472 0,3472<1.96 , следовательно согласно критерию гетероскедастичность линейного вида отсутствует.
Rх.е =-0,3472 0,3472<1.96 , следовательно согласно критерию гетероскедастичность линейного вида отсутствует.Проверим наличие гетероскедастичности по переменной Х9
![]()
![]()
![]()
![]()
Приведем график зависимости регрессионных остатков
![]() от изменения признака Х9.
от изменения признака Х9.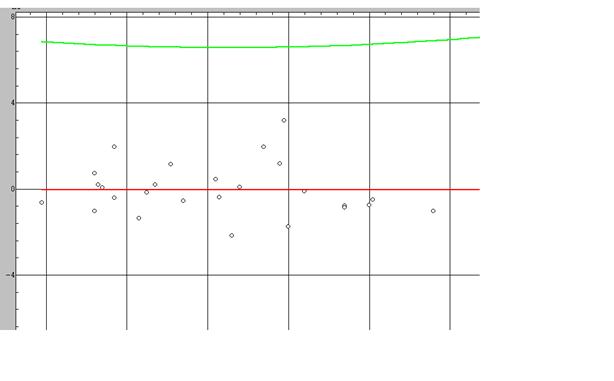
По оси ординат (У) отражено значение остатков , по оси абсцисс (х) значение признака. Как видно визуально гетероскедастичность отсутствует.
Ранговый коэффициент корреляции будет Rx,e= -0,1364, t=
![]() Rх.е =-0,6955 0,6955<1.96 , следовательно согласно критерию гетероскедастичность линейного вида отсутствует.
Rх.е =-0,6955 0,6955<1.96 , следовательно согласно критерию гетероскедастичность линейного вида отсутствует.3. Устранение гетероскедастичности обобщенным методом наименьших квадратов.
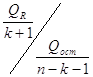 , где QR=(Xb)ТΩ-1(Хb) , Qост=(У-Хb)ТΩ-1(У-Хb)
, где QR=(Xb)ТΩ-1(Хb) , Qост=(У-Хb)ТΩ-1(У-Хb)![]() , где Sbj=Ŝ ( ( XТΩ-1Х)-1)jj
, где Sbj=Ŝ ( ( XТΩ-1Х)-1)jj![]() , Ŝ=
, Ŝ=![]()
4. Исследование модели на наличие автокорреляции.
![]() и нижнюю
и нижнюю![]() границы для критического значения статистики. Возможны три ситуации:
границы для критического значения статистики. Возможны три ситуации: ![]() , то нет автокорреляции;
, то нет автокорреляции; ![]()
![]()
![]() =
=![]() +
+![]() , где
, где ![]() <1;
<1; ![]() -случайные величины, обладающие свойствоми: М
-случайные величины, обладающие свойствоми: М![]() =0; D
=0; D![]() =
=![]() , cov(
, cov(![]() ,
,![]() ) =0 при i
) =0 при i![]() j т.е. относительно
j т.е. относительно ![]() мы имеем линейную регрессионную гомоскедастичную модель. Наша цель- построить ковариационную матрицу вектора регрессионных остатков, найти ее оценку и построить модель ОМНК. Исследуем случайные величины
мы имеем линейную регрессионную гомоскедастичную модель. Наша цель- построить ковариационную матрицу вектора регрессионных остатков, найти ее оценку и построить модель ОМНК. Исследуем случайные величины ![]() :
: ![]() М
М![]() =
= ![]()
![]() М
М![]() =0
=0 ![]() D
D![]() =
=![]()
![]() , т.е. дисперсия регрессионных остатков постоянная величина.
, т.е. дисперсия регрессионных остатков постоянная величина. ![]()
![]() =
=![]()
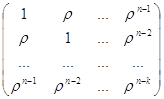
![]() можно указать
можно указать ![]() .
. ![]()
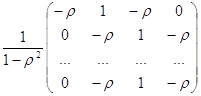
![]() неизвестна. Рассмотрим способом оценивания с помощью метода Кокрейна-Оркатта, который представляет собой итерационный подход, включающий следующие этапы:
неизвестна. Рассмотрим способом оценивания с помощью метода Кокрейна-Оркатта, который представляет собой итерационный подход, включающий следующие этапы: ![]()
![]() ;
;![]() ;
; ![]() от е
от е![]() : е
: е![]() =
=![]() , коэффициент при е
, коэффициент при е![]() представляет оценку
представляет оценку ![]()
![]() ,
, ![]() . Используя эту матрицу оцениваем регрессионную зависимость У от Х ОМНК.
. Используя эту матрицу оцениваем регрессионную зависимость У от Х ОМНК. ![]() процесс возвращается к пункту 3.
процесс возвращается к пункту 3. ![]() на последнем и предпоследнем этапах будут примерно одинаковыми.
на последнем и предпоследнем этапах будут примерно одинаковыми. ![]() , в случае зависимости регрессионных остатков первого порядка. Используя матрицу
, в случае зависимости регрессионных остатков первого порядка. Используя матрицу ![]() можно построить вектор оценок коэффициентов регрессии ОМНК, проверить на значимость уравнение регрессии, построить доверительные интервалы по вышеописанным формулам
можно построить вектор оценок коэффициентов регрессии ОМНК, проверить на значимость уравнение регрессии, построить доверительные интервалы по вышеописанным формулам![]()
![]()
![]()
![]()
0.917
2.18
0.808
-5
-7.52
-17.5
7.55
-10.2
11.5
-21.7
2.23
0.909
-7.49
19.7
4.75
-10.3
11.9
10.8
-4.14
-8.63
-6.32
-13.4
-3.89
-5.4
-1.42
19.6
2.18
0.808
-5
-7.52
-17.5
7.55
-10.2
11.5
-21.7
2.23
0.909
-7.49
19.7
4.75
-10.3
11.9
10.8
-4.14
-8.63
-6.32
-13.4
-3.89
-5.4
-1.42
19.6
32
9,59141
1,88238
33,7329
6,3504
99,6004
627,502
315,063
470,89
1102,24
572,645
1,74504
70,5432
739,296
223,502
226,503
492,84
1,21
223,204
20,1601
5,3361
50,1264
90,4401
2,2801
15,8404
441,84
153,76
0,840889
4,7524
0,652864
25
56,5504
306,25
57,0025
104,04
132,25
470,89
4,9729
0,826281
56,1001
388,09
22,5625
106,09
141,61
116,64
17,1396
74,4769
39,9424
179,56
15,1321
29,16
2,0164
384,16
Посчитаем критерий Дарбина-Уотсона:
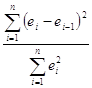 =5998.124/2736.788= 2.191
=5998.124/2736.788= 2.1915. Устранение автокорреляции 1 – го порядка обобщенным методом наименьших квадратов.
![]() :
: ![]() М
М![]() =
= ![]()
![]() М
М![]() =0
=0 ![]() D
D![]() =
=![]()
![]() , т.е. дисперсия регрессионных остатков постоянная величина.
, т.е. дисперсия регрессионных остатков постоянная величина. ![]()
![]() =
=![]()
![]() можно указать
можно указать ![]() .
. ![]()
![]() неизвестна. Рассмотрим способом оценивания с помощью метода Кокрейна-Оркатта, который представляет собой итерационный подход, включающий следующие этапы:
неизвестна. Рассмотрим способом оценивания с помощью метода Кокрейна-Оркатта, который представляет собой итерационный подход, включающий следующие этапы: ![]()
![]() ;
;![]() ;
; ![]() от е
от е![]() : е
: е![]() =
=![]() , коэффициент при е
, коэффициент при е![]() представляет оценку
представляет оценку ![]()
![]() ,
, ![]() . Используя эту матрицу оцениваем регрессионную зависимость У от Х ОМНК.
. Используя эту матрицу оцениваем регрессионную зависимость У от Х ОМНК. ![]() процесс возвращается к пункту 3.
процесс возвращается к пункту 3. ![]() на последнем и предпоследнем этапах будут примерно одинаковыми.
на последнем и предпоследнем этапах будут примерно одинаковыми. ![]() , в случае зависимости регрессионных остатков первого порядка. Используя матрицу
, в случае зависимости регрессионных остатков первого порядка. Используя матрицу ![]() можно построить вектор оценок коэффициентов регрессии ОМНК, проверить на значимость уравнение регрессии, построить доверительные интервалы по вышеописанным формулам.
можно построить вектор оценок коэффициентов регрессии ОМНК, проверить на значимость уравнение регрессии, построить доверительные интервалы по вышеописанным формулам.Приложение 1
Исходные данные *
№ п/п ![]()
Центрированная матрица
№ п/п