Практическое кодирования по Хэммингу
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИНФОРМАТИКИ И РАДИОЭЛЕКТРОНИКИ
кафедра РЭС
реферат на тему:
«Практическое кодирования по Хэммингу»
МИНСК, 2009
Пусть нам предстоит закодировать текст, записанный на некотором языке, таком, что число букв в алфавите этого языка n = 2m (m целое число), а появление в тексте тех или иных букв алфавита равновероятно и не зависит от того, какие буквы им предшествовали. Тогда имеем
p(i) = p(j) = 1/n; H = log2 = m.
Условия задачи таковы, что достичь оптимального кодирования можно самым незатейливым методом кодирования - побуквенным кодированием с постоянной длиной (l = m) кодовых наборов. При этом, однако, мы оказались бы лишенными какой-либо возможности обнаруживать, а тем более исправлять ошибки. Чтобы такая возможность появилась, необходимо отказаться от оптимальности кода, "раскошелиться" на несколько дополнительных двоичных символов на букву, т.е. умышленно ввести некоторую избыточность, которая смогла бы помочь нам обнаружить или исправить ошибки. Необходимое число дополнительно вводимых двоичных символов на одну букву обозначим через x, и тогда длина кодового набора станет равной l = m + x. Примем, что в результате помех (случайных или преднамеренных) лишь один или вовсе никакой из m + x двоичных символов может превращаться из единицы в нуль или, наоборот, из нуля в единицу. Примем далее, что 1 + m + x событий, заключающиеся в том, что ошибка вообще не произойдет, произойдет на уровне первого, второго, .... (m + x)-го символа кодового набора, равновероятны. Энтропию угадывания того, какое именно из этих 1 + m + x событий будет иметь место, в силу равновероятности этих событий можно определить по формуле Н = log2 (1 + m + х) бит. Таким образом, для обнаружения самого факта наличия одиночной ошибки и установления ее позиции необходимо заполучить информацию в количестве не менее Н = log2(1 + m + x) бит. Источником этой информации служат лишь дополнительно введенные x двоичных символов, так как остальные m символов из-за оптимальности кодирования до предела заняты описанием самого текста. Заметим, что x двоичных символов в лучшем случае могут содержать информацию в количестве x бит. Таким образом, при конструировании кода, обнаруживающего и исправляющего одиночную ошибку, следует учесть, что этого можно добиться лишь при значениях x, удовлетворяющих неравенству
х>= log2(l+m+x),
или 2x-x-1>=m.
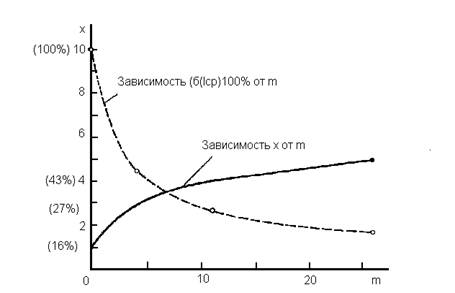
Рис. 1.Зависимость нижней границы допустимых значений x от m (сплошная линия) и зависимость относительной избыточности от m (пунктирная линия).
Р. Хэмминг разработал конкретную конструкцию кода. которая обеспечивает весьма элегантное обнаружение и исправление одиночных ошибок при минимально возможном числе дополнительно вводимых двоичных символов, т.е. при знаке равенства. Проследим за построением этого кода, когда m = 4. Из рисунка следует, что при этом допустимое значение x равно трем, т.е. при числе основных (информационных) двоичных символов m = 4, число дополнительно введенных, т.е. контрольных символов должно быть не менее трех. Примем, что нам удалось "обойтись" именно тремя дополнительными символами, т.е. удалось сконструировать такой код, при котором каждый из дополнительно введенных трех символов дает нам максимально возможное количество информации, т.е. по одному биту. Тогда в расширенном кодовом наборе окажутся семь двоичных символов:
B1B2B3B4 B5B6B7
(информационные символы) (контрольные символы)
Поскольку символы B1 - B4 заняты кодированием собственно текста, то управлять их значениями нам не дано. Что же касается символов B5 - B7, то они предназначены именно для обнаружения и исправления ошибок и поэтому их значения мы можем увязать со значениями информационных символов произвольными тремя функциями от аргументов B1 - B4:
B5=B5(B1,...,B4) (1)
B6=B6(B1,...,B4) (2)
B7=B7(B1,...,B4) (3)
такими, чтобы в последующем с помощью трех других функций от аргументов B1 - B7
e0=e0(B1-B7) (4)
e1=e1(B1-B7) (5)
e2=e2(B1-B7) (6)
определить значения e0,e1,e2 содержащие информацию о том, произошла ли ошибка вообще и если да, то на уровне какого именно из семи символов. Очевидно, имеется множество различных вариантов при выборе функций (1)- (6). Р. Хэмминг поставил перед собой задачу выбора именно такой совокупности функций (1) - (6), чтобы набор значений e2e1e0 оказался двоичной записью позиции, где произошла ошибка. В случае же, когда ошибка не имела места, набор e2e1e0 должен указать на нулевую позицию, т.е. на несуществующий символ B0. Из двоичной записи этих позиций
000 (0) 1 0 0 (7)
001 (1) 1 0 1 (8)
010 (2) 1 1 0 (9)
011 (3) 1 1 1 (10)
легко уследить, что значение e0 "несет ответственность" за позиции B1, B3, B5 и B7 и поэтому в качестве функции (1.14) берется зависимость
e0 = B1+B3+B5+B7 mod 2. (11)
Аналогично, обращая внимание на то, что значения e1 и e2 отвечают за соответственно B2 B3 B6 B7 , B4 B5 B6 B7, получим
e1= B2+B3+B6+B7 mod 2, (12)
e2= B4+B5+B6+B7 mod 2. (13)
Обратим внимание, что систему (1.14а) - (1.16а) можно рассматривать как развернутую запись матричного уравнения
B1
B2
e0 1010101 B3
e1 = 0110011 B4
e2 0001111 B5
B6
B7
или
Ve=AVa,
где Ve, - вектор ошибки, указывающий на ее месторасположение; А - основная матрица, столбцы которой суть двоичные записи чисел от одного до семи.
Операция сложения во всех трех уравнениях (14) - (16) осуществляется по модулю два. Подставляя в систему уравнении (14) - (16) e0=e1=e2=0, получим систему из трех уравнений
B1+B1+B5+B7=0 mod2 (14)
B2+B3+B6+B7=0 mod2 (15)
B4+B5+B6+B7=0 mod2, (16)
Приняв в качестве неизвестных величины B5, B6 и B7 получим систему из трех уравнений с тремя неизвестными:
B5+B7=B1+B3 mod2, (17)
B6+B7=B2+B3 mod2, (18)
B5+B6+B7=B4 mod2. (19)
Эта система эквивалентна одному матричному уравнению
B1
101 B5 1010 B2
011 B6 = 0110 B3 (20)
111 B7 0001 B4
или
CVe=IVi. (21)
где Ve и Vi, векторы-столбцы, координаты которых представлены соответственно контрольными и информационными разрядами; С и I - так называемые контрольная и информационная матрицы. Столбцы этих матриц суть двоичные записи номеров соответственно контрольных и информационных разрядов.
Решение системы (17) - (19), или. что то же самое, матричного уравнения (20) относительно B5, B6, B7 приводит к конкретным выражениям для функций (1) -(3):
B5=B2+B3+B4 mod2, (22)
B6=B1+B3+B4 mod2, (23)
B7=B1+B2+B4 mod2. (24)
Заметим, что сам Р. Хэмминг в качестве контрольного берет не набор символов B(m+1),B(m+2), ...B(m+x), а нaбор символов, индексы которых представляют целые степени двойки. В случае, когда число контрольных символов равно трем, эти индексы равны 20 =1, 21 = 2 и 22 = 4, т.е. речь идет о наборе символов B1B2B4, относительно которых решение системы (14) - (16) чрезвычайно упрощается:
B1=B3+B5+B7 mod 2,
B2=B3+B6+B7 mod 2,
B4=B5+B6+B7 mod 2.
Это и естественно, поскольку в данном случае вместо (17) имеем дело с матричным уравнением
B3
1 0 0 B1 B5
0 1 0 B2 = B6
0 0 1 B4 B7
где контрольная матрица С всегда равна единичной матрице.
Отметив, что при указанной рекомендации Р. Хэмминга контрольная матрица всегда (независимо от m и x) оказывается равной единице, подробное обсуждение этой рекомендации оставим на потом, продолжая рассматривать в качестве контрольных B5B6B7 а качестве информационных - B1B2B3B4.
Рассмотрим, к примеру, набор информационных символов B1B2B3B4 = 1011. С помощью зависимостей (22) - (24) определим набор контрольных (дополнительно введенных, избыточных) символов B5B6B7 = 010. Пусть ошибка произошла на уровне символа B5 т.е. вместо истинного расширенного кодового набора 1011 (0)10 получен код 1011 (1)10. Тогда с помощью зависимостей (14)- (16) найдем
e0=1+1+1+0=1 mod2,
e1=0+1+1+0=0 mod2,
e2=1+1+1+0=1 mod2.
Набор значений e2e1e0=101 является двоичной записью числа "пять", т.е. указывает именно на пятую позицию (на символ B5), где, собственно, и произошла ошибка.
Приведенная схема Р. Хэмминга по конструированию кода, обнаруживающего и исправляющего одиночную ошибку, универсальна, и аналогичный код может быть построен для произвольной пары значений m и x, удовлетворяющих уравнению
2х- х - 1 = m. (25)
Заметим также, что вовсе не обязательно, чтобы набор из m информационных символов представлял собой код какой-то определенной буквы, как это имело место в только что рассмотренном примере. На практике сначала можно осуществить оптимальное (или близкое к оптимальному) кодирование текста. Затем уже закодированный текст можно делить на блоки по m двоичных символов в каждом, причем из возможных значений m = 2x - х - 1 (х = 3, 4, ...) его конкретное значение следует выбирать исходя из эксплуатационной необходимости. При прочих равных условиях значение m должно быть тем меньшим, чем больше значимость информации и чем больше уровень помех. После выбора конкретного значения m каждый блок из m информационных символов следует наращивать х = х (m) контрольными символами, предназначенными для обнаружения и исправления одиночных ошибок в рамках данного блока.
А теперь вернемся к рассмотрению вопроса о том, почему Р. Хэмминг в качестве контрольных берет именно символы, индексы которых равны целым степеням двойки, т.е. 1, 2, 4, 8, 16,.... Во-первых, как уже об этом говорилось выше, при таком выборе контрольная матрица всегда оказывается равной единице, т.е. фактически снимается вопрос решения системы (22)-(24) относительно контрольных символов, так как ее "решение" сводится к простому переписыванию соответствующих уравнений. Но это не главное, так как систему (22)-(24) приходится решать только один раз и далее при каждом акте кодирования мы пользуемся лишь системой (11) - (13) - решением системы (22)-(24) относительно контрольных символов. При реализации процедур кодирования и декодирования на ЭВМ сам факт, что контрольные символы разобщены (не следуют подряд друг за другом), создает определенные неудобства при каждом акте кодирования и декодирования. Естественно поэтому желание выбрать контрольные символы таковыми, чтобы они следовали подряд друг за другом, пусть даже ценою того, чтобы один раз решить систему (14) - (16). Именно так поступали мы, когда вопреки рекомендации Р. Хэмминга взять в качестве контрольных символы B1,B2 и B4 взяли в качестве таковых символы B5, B6 и B7. Хотя это и вынудило нас решить систему относительно переменных B5, B6 и B7, но зато при каждом акте кодирования и декодирования мы смогли оперировать "пачками" контрольных символов, а не "выковыривать" их среди информационных символов.
Возникает вопрос; а всегда ли, при любом числе информационных символов мы смогли бы поступать аналогичным образом? Нет, не смогли бы, если по-прежнему хотим, чтобы двоичный набор символов ex-1,ex-2,...,e0 указывал на адрес ошибки. Потому что уже когда число контрольных символов больше трех, мы не имеем права взять в качестве контрольных последние х символов. Легко убедиться, что при этом контрольная матрица непременно оказалась бы вырожденной, т.е. значение ее детерминанта оказалась бы равным нулю. Более того, даже в рассмотренном нами случае, когда число контрольных символов равно трем, мы не смогли бы в качестве контрольных взять, например, первые три символа. Во всех этих случаях определители контрольных матриц (вспомним, что столбцы этой матрицы суть двоичные записи номеров выбранных нами контрольных символов) оказываются равными нулю. Пусть, например, мы выбрали в качестве контрольных не пачку символов B5, B6, B7, а символы B1, B2, B3. Тогда нам пришлось бы иметь дело с квадратной матрицей третьего порядка, столбцы которой являются двоичными формами записи чисел 1, 2 и 3:
101
С = 011 .
000
Равенство нулю детерминанта этой матрицы свидетельствует о том, что систему (1.14б) - (1.16б) нельзя решить относительно переменных B1, B2, B3.
Таким образом, при выборе среди m + x символов x контрольных следует заботиться о том, чтобы определитель контрольной матрицы порядка x, столбцы которой представляют собой двоичные записи номеров выбранных символов, не оказался равным нулю. Именно чтобы избавиться от этих забот, Р. Хэмминг рекомендует в качестве контрольных взять символы с индексами I, 2, 4, 8 и т.д. Легко обнаружить, что при таком выборе контрольных символов мы всегда (независимо от их числа) будем иметь дело с единичной матрицей.
Кроме зависимости (10). на рисунке приведена также зависимость относительной избыточности от m. Легко заметить, что с увеличением m требуемый процент избыточности для обнаружения и исправления одиночной ошибки резко уменьшается. Столь неестественный результат является следствием искусственного, далекого от реальности допущения, что в рамках каждого кодового набора независимо от его длины m + x может произойти не более одной ошибки. Если же допустить возможность двух и более ошибок, то задача их обнаружения, и тем более исправления усложняется. Построить для этих случаев коды столь же элегантные, как код Р. Хэммннга для одиночной ошибки, пока не удалось.
ЛИТЕРАТУРА
1. Лидовский В.И. Теория информации. - М., «Высшая школа», 2002г. – 120с.
2. Метрология и радиоизмерения в телекоммуникационных системах. Учебник для ВУЗов. / В.И.Нефедов, В.И.Халкин, Е.В.Федоров и др. – М.: Высшая школа, 2001 г. – 383с.
3. Цапенко М.П. Измерительные информационные системы. - . – М.: Энергоатом издат, 2005. - 440с.
4. Зюко А.Г. , Кловский Д.Д., Назаров М.В., Финк Л.М. Теория передачи сигналов. М: Радио и связь, 2001 г. –368 с.
5. Б. Скляр. Цифровая связь. Теоретические основы и практическое применение. Изд. 2-е, испр.: Пер. с англ. – М.: Издательский дом «Вильямс», 2003 г. – 1104 с.